This is the transcript of the talk I gave today at the Digital Pedagogy Lab at the University of Prince Edward Island. You can find the slides here. Image and data credits are listed at the bottom of this post.

Last summer, when I gave a keynote at the Digital Pedagogy Lab Summer Institute in Madison, Wisconsin, I talked about “teaching machines and Turing machines,” tracing some of the origins of artificial intelligence and scrutinizing the work that those of us in education – students, teachers, administrators – are increasing asking software and hardware to do.
I’ve long been interested in the push for automation and AI in education – certainly, talk of “robots coming for our jobs” is not new, and predictions by technologists about the impending arrival of artificial intelligence are now sixty some odd years old – that is, for decades, we’ve heard people tell us that we’re just a decade or so away from AI being able to do any job a human can. Let me make sure I’m clear here – I’m interested in the “push,” in the stories we tell about machines more so than the technology underpinning the machines themselves.
As I was in Wisconsin last summer, I wanted to speak directly to issues surrounding AI, teaching machines, and threats to labor, particularly as the state was in the middle (is in the middle) of a political battle over the future of public workers’ rights and the future of tenure at its public universities. But I also wanted to tease out, more generally, what we mean by the labor of teaching and learning, how the former in particular is gendered, how the labor practices in education are not simply a matter of the rational distribution or accumulation of facts, and how and why (and if) our meanings and values surrounding teaching and learning labor will shape the ways in which education is automated. If education is automated. Whose education is automated.
Consider this a companion talk.

As the title suggests, I want to talk today not about “teaching machines” or “Turing machines” but about “memory machines.” These machines are all kin, of course. They’re part of our cultural imaginary as much as they are about a technological reality that we face today. These machines are all intertwined with how we imagine the future of intelligence and knowledge, along with the future of the institutions traditionally responsible for these things – namely schools, universities, libraries, museums.
There are powerful narratives being told about the future that insist we are at a moment of extraordinary technological change. That change, according to these tales, is happening faster than ever before. It is creating an unprecedented explosion in the production of information. New information technologies, so we’re told, must therefore change how we learn – change what we need to know, how we know, how we create knowledge. Because of the pace of change and the scale of change and the locus of change – again, so we’re told – our institutions, our public institutions can no longer keep up. These institutions will soon be outmoded, irrelevant. So we’re told.
Powerful narratives, like I said. But not necessarily true. And even if partially true, we are not required to respond the way those in power or in the technology industry would like.

As Neil Postman and others have cautioned us, technologies tend to become mythic – unassailable, God-given, natural, irrefutable, absolute. And as they do so, we hand over a certain level of control – to the technologies themselves, sure, but just as importantly to the industries and the ideologies behind them. Take, for example, the founding editor of the technology trade magazine Wired, Kevin Kelly. His 2010 book was called What Technology Wants, as though technology is a living being with desires and drives; the title of his 2016 book, The Inevitable. We humans, in this framework, have no agency, no choice. The future – a certain flavor of technological future – is pre-ordained.
So is the pace of technological change accelerating? Is society adopting technologies faster than it’s ever done before? Perhaps it feels like it. It certainly makes for a good headline, a good stump speech, a good keynote, a good marketing claim. (A good myth. A dominant ideology.) But the claim falls apart under scrutiny.
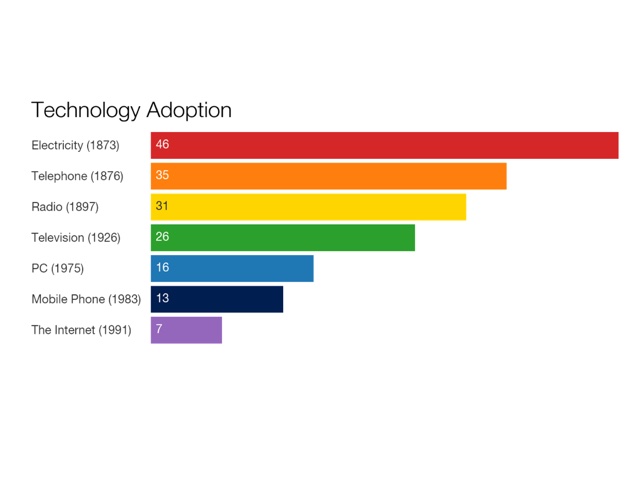
This graph comes from an article in the online publication Vox that includes a couple of those darling made-to-go-viral videos of young children using “old” technology like rotary phones and portable cassette players – highly clickable, highly sharable stuff. The visual argument in the graph: the number of years it takes for one quarter of the US population to adopt a new technology has been shrinking with each new innovation.
But the data is flawed. Some of the dates given for these inventions are questionable at best, if not outright inaccurate. If nothing else, it’s not so easy to pinpoint the exact moment, the exact year when a new technology came into being. There often are competing claims as to who invented a technology and when, for example, and there are early prototypes that may or may not “count.” James Clerk Maxwell did publish A Treatise on Electricity and Magnetism in 1873. Alexander Graham Bell made his famous telephone call to his assistant in 1876. Guglielmo Marconi did file his patent for radio in 1897. John Logie Baird demonstrated a working television system in 1926. The MITS Altair 8800, an early personal computer that came as a kit you had to assemble, was released in 1975. Martin Cooper, a Motorola exec, made the first mobile telephone call in 1973, not 1983. And the Internet? The first ARPANET link was established between UCLA and the Stanford Research Institute in 1969. The Internet was not invented in 1991.
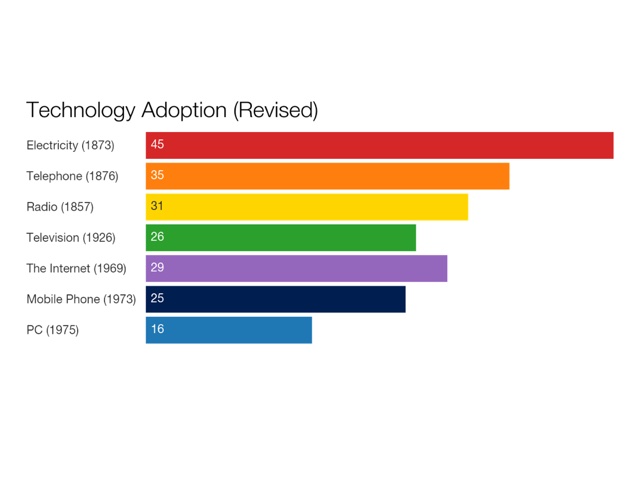
So we can reorganize the bar graph. But it’s still got problems.
The Internet did become more privatized, more commercialized around that date – 1991 – and thanks to companies like AOL, a version of it became more accessible to more people. But if you’re looking at when technologies became accessible to people, you can’t use 1873 as your date for electricity, you can’t use 1876 as your year for the telephone, and you can’t use 1926 as your year for the television. It took years for the infrastructure of electricity and telephony to be built, for access to become widespread; and subsequent technologies, let’s remember, have simply piggy-backed on these existing networks. Our Internet service providers today are likely telephone and TV companies.
Economic historians who are interested in these sorts of comparisons of technologies and their effects typically set the threshold at 50 percent – that is, how long does it take after a technology is commercialized (not simply “invented”) for half the population to adopt it. This way, you’re not only looking at the economic behaviors of the wealthy, the early-adopters, the city-dwellers, and so on (but to be clear, you are still looking at a particular demographic – the privileged half.)
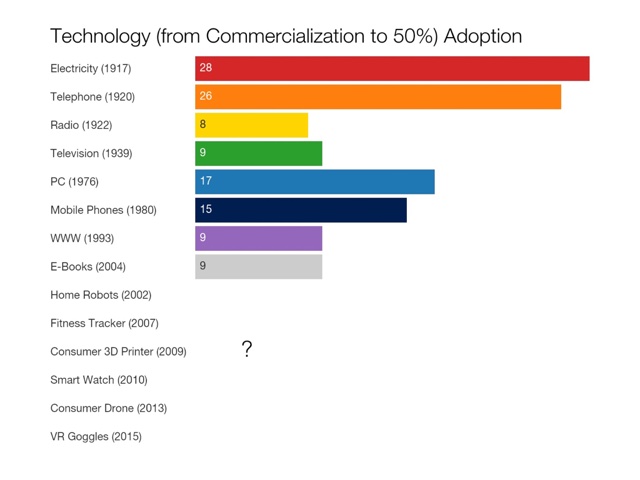
How many years do you think it’ll be before half of US households (or Canadian ones) have a smart watch? A drone? A 3D printer? Virtual reality goggles? A self-driving car? Will they? Will it be fewer years than 9? I mean, it would have to be if, indeed, “technology” is speeding up and we are adopting new technologies faster than ever before.
Some of us might adopt technology products quickly, to be sure. Some of us might eagerly buy every new Apple gadget that’s released. But we can’t claim that the pace of technological change is speeding up just because we personally go out and buy a new iPhone every time Apple tells us the old model is obsolete.

Some economic historians like Robert J. Gordon actually contend that we’re not in a period of great technological innovation at all; instead, we find ourselves in a period of technological stagnation. The changes brought about by the development of information technologies in the last 40 years or so pale in comparison, Gordon argues (and this is from his recent book The Rise and Fall of American Growth: The US Standard of Living Since the Civil War), to those “great inventions” that powered massive economic growth and tremendous social change in the period from 1870 to 1970 – namely electricity, sanitation, chemicals and pharmaceuticals, the internal combustion engine, and mass communication.
We are certainly obsessed with “innovation” – there’s this rather nebulously defined yet insistent demand that we all somehow do more of it and soon.
Certainly, we are surrounded by lots of new consumer technology products today that beckon to us to buy buy buy the latest thing. But I think it’s crucial, particularly in education, that we do not confuse consumption with innovation. Buying hardware and buying software does not make you or your students or your institutions forward-thinking. We do not have to buy new stuff faster than we’ve ever bought new stuff before in order to be “future ready.” (That’s the name of the US Department of Education initiative, incidentally, that has school districts promise to “buy new stuff.”)
We can think about the changes that must happen to our educational institutions not because technology compels us but because we want to make these institutions more accessible, more equitable, more just. We should question this myth of the speed of technological change and adoption – again, by “myth” I don’t mean “lie”; I mean “story that is unassailably true.” – if it’s going to work us into a frenzy of bad decision-making. Into injustice. Inequality.
We have time – when it comes to technological change – to be thoughtful. (We might have less time when it comes to climate change or to political pressures – these challenges operate on their own, distinct time tables.) I’m not calling for complacency, to be clear. Quite the contrary. I’m calling for critical thinking.

We should question too the myth that this is an unprecedented moment in human history because of the changes brought about by information and consumer technologies. This is not the first or only time period in which we’ve experienced “information overload.” This is not the first time we have struggled with “too much information.” The capacity of humans’ biological memory has always lagged behind the amount of information humans have created. Always. So it’s not quite right to say that our current (over)abundance of information began with computers or was caused by the Internet.
Often, the argument that there’s “too much information” involves pointing to the vast amounts of data that is created thanks to computers. Here’s IBM’s marketing pitch, for example:
Every day, we create 2.5 quintillion bytes of data – so much that 90% of the data in the world today has been created in the last two years alone. This data comes from everywhere: sensors used to gather climate information, posts to social media sites, digital pictures and videos, purchase transaction records, and cell phone GPS signals to name a few. This data is big data.
IBM is, of course, selling its information management services here. They’re selling data storage – “big data” storage. Elsewhere they’re heavily marketing their artificial intelligence product, IBM Watson, which is also reliant on “big data” mining.
Again, these numbers demand some scrutiny. Marketing figures are not indisputable facts. Just because you read it on the Internet, doesn’t make it true. It’s not really clear how we should count all this data. Does it still count if it gets deleted? Do we count it if it’s unused or unexamined or if it’s metadata or solely machine-readable? Should we count it only if it’s human-readable? Do we only count information now only if it’s stored in bits and bytes?
Now, I’m not arguing that there isn’t more data or “big data.” What I want us to keep in mind is that humans throughout history have felt overwhelmed by information, by knowledge known and unknown. We’re curious creatures, we humans; there’s always been more to learn, always been more to learn than is humanly possible.
With every new “information technology” that humans have invented – dating all the way back to the earliest writing and numeric systems, back to the ancient Sumerians and cuneiform, for example – we have seen an explosion in the amount of information produced and as a result, we’ve faced crises, again and again, over how this surplus of information will be stored and managed and accessed and learned and taught. (Hence, the development of the codex, the index, the table of contents, for example. The creation of the library.) According to one history of the printing press, by 1500 – only five decades or so after Johannes Gutenberg published his famous Bible – there were between 150 and 200 million books in circulation in Europe.
All this is to say, that ever since humans have been writing things down, there have been more things to read and learn than any one of us could possibly read and learn.
But that’s okay, because we can write things down. We can preserve ideas – facts, figures, numbers, stories, observations, research, ramblings – for the future. Not just for ourselves to read later, but to extend beyond our lifetime. (The challenge for education – then and now – in the face of the overabundance of information has always been, in part, to determine what pieces of information should be “required knowledge.” Not simply “required knowledge” for a test or for graduation, but “required knowledge” to move you towards a deeper understanding of a topic, towards expertise perhaps.)

Of course, the great irony is that “writing things down” preserved one of the most famous criticisms of the technology of writing – Socrates in Plato’s Phaedrus.
Plato tells the story of Socrates telling a story in turn of a meeting between the king of Egypt, Thamus, and the god Theuth, the inventor of many arts including arithmetic and astronomy. Theuth demonstrates his inventions for the king, who does not approve of the invention of writing.
But when they came to letters, This, said Theuth, will make the Egyptians wiser and give them better memories; it is a specific both for the memory and for the wit. Thamus replied: O most ingenious Theuth, the parent or inventor of an art is not always the best judge of the utility or inutility of his own inventions to the users of them. And in this instance, you who are the father of letters, from a paternal love of your own children have been led to attribute to them a quality which they cannot have; for this discovery of yours will create forgetfulness in the learners’ souls, because they will not use their memories; they will trust to the external written characters and not remember of themselves. The specific which you have discovered is an aid not to memory, but to reminiscence, and you give your disciples not truth, but only the semblance of truth; they will be hearers of many things and will have learned nothing; they will appear to be omniscient and will generally know nothing; they will be tiresome company, having the show of wisdom without the reality.
Plato makes it clear in Phaedrus that Socrates shares Thamus’s opinion of writing – a deep belief that writing enables a forgetfulness of knowledge via the very technology that promises its abundance and preservation. “He would be a very simple person,” Socrates tells Phaedrus, “who deemed that writing was at all better than knowledge and recollection of the same matters.”
Writing will harm memory, Socrates argues, and it will harm the truth. Writing is insufficient and inadequate when it comes to teaching others. Far better to impart knowledge to others via “the serious pursuit of the dialectician.” Via a face-to-face exchange. Via rhetoric. Via discussion. Via direction instruction.
Or now, some two thousand years later, we debate whether it’s better to take notes by hand in class or to use the computer. We’re okay with writing as a technology now; it’s this new information technology that causes us some concern about students’ ability to remember.
Information technologies do change memory. No doubt. Socrates was right about this. But what I want to underscore in this talk is not just how these technologies affect our individual capacity to remember but how they also serve to extend memory beyond us.

By preserving memory and knowledge, these technologies have helped create and expand collective memory – through time and place. We can share this collective memory. This collective memory is culture – that is, the sharable, accessible, alterable, transferable knowledge we pass down from generation to generation and pass across geographical space, thanks to information technologies. The technologies I pointed to earlier – the telephone, radio, television, the Internet, mobile phones – these have all shifted collective memory and culture, as of course the printing press did before that.
One of the challenges that education faces is that, while we label its purpose – one of its purposes – as “the pursuit of knowledge,” we’re actually greatly interested in and responsible for “the preservation of knowledge,” for the extension of collective memory. Educational institutions, at advanced levels, do demand the creation of new knowledge. But that’s not typically the task that’s assigned to most students – for them, it’s about learning about existing knowledge, committing collective memory to personal memory.

One of the problems with this latest information technology is that we use the word “memory,” a biological mechanism, to describe data storage. We use the word in such a way that suggests computer memory and human memory are the same sort of process, system, infrastructure, architecture. They are not. But nor are either human or computer memory quite the same as some previous information technologies, those to which we’ve outsourced our “memory” in the past.
Human memory is partial, contingent, malleable, contextual, erasable, fragile. It is prone to embellishment and error. It is designed to filter. It is designed to forget.
Most information technologies are not. They are designed to be much more durable than memories stored in the human brain. These technologies fix memory and knowledge, in stone, on paper, in moveable type. From these technologies, we have gained permanence, stability, unchangeability, materiality.
Digital information technologies aren’t quite any of those. Digital data is more robust, perhaps. It doesn’t just include what you wrote but when you wrote it, how long it took you to write it, how many edits, and so on. But as you edit, it’s pretty apparent: digital data is easy overwritten; it is easily erased. It’s stored in file formats that – unlike the alphabet, a technology that’s thousands of years old – can become quickly obsolete, become corrupted. Digital data is reliant on machines in order to be read – that means too these technologies are reliant on electricity or on battery power and on a host of rare earth materials, all of which do take an environmental and political toll. Digital information is highly prone to decay – even more than paper, ironically enough, which was already a more fragile and flammable technology than the stone tablets that it replaced. It was more efficient, of course, to write on paper than to carve stone. And as a result, humans created much more information when we moved from stone to paper and then from writing by hand to printing by machine. But what we gained in efficiency, all along the way we have we lost in durability.
If you burn down a Library of Alexandria full of paper scrolls, you destroy knowledge. If you set fire to a bunch stone tablets, you further preserve the lettering. Archeologists have uncovered tablets that are thousands and thousands of years old. Meanwhile, I can no longer access the data I stored on floppy disks twenty years ago. My Macbook Air doesn’t read CD-ROMs, the media I used to store data less than a decade ago.

The average lifespan of a website, according to the Internet Archive’s Brewster Kahle is 44 days – and again, much like the estimates about the amount of data we’re producing, there really aren’t any reliable measures here (it’s actually quite difficult to measure). That is, the average length of time from when a web page is created and when the URL is no longer accessible is about a month and a half. Research conducted by Google pegged the amount of time that certain malware-creating websites stay online is less than two hours, and certainly this short duration along with the vast number of sites spun up for these nefarious purposes skews any sort of “average.” Geocities lasted fifteen years; MySpace lasted about six before it was redesigned as an entertainment site; Posterous lasted five. But no matter the exact lifespan of a website, we know, in general, it’s pretty short. According to a 2013 study, half of the links cited in US Supreme Court decisions – and this is certainly the sort of thing we’d want to preserve and learn from for centuries to come – are already dead.
Web service providers shut down, websites go away, and even if they stay online, they regularly change (sometimes with little indication that they’ve done so). “Snapshots” of some 491 billion web pages have been preserved, thanks to the work of the San Francisco-based non-profit the Internet Archive, by the “Wayback Machine” which does offer us some ability to browse archived Web content, including from sites that no longer exist. But not all websites allow the Wayback Machine to index them. It’s an important but partial effort.
We might live in a time of digital abundance, but our digital memories – our personal memories and our collective memories – are incredibly brittle. We might be told we’re living in a time of rapid technological change, but we are also living in a period of rapid digital data decay, of the potential loss of knowledge, the potential loss of personal and collective memory.

“This will go down on your permanent record” – that’s long been a threat in education. And we’re collecting more data than ever before about students. But what happens to it? Who are the stewards of digital data? Who are the stewards of digital memory? Of culture?
With our move to digital information technologies, we are entrusting our knowledge and our memories – our data, our stories, our status updates, our photos, our history – to third-party platforms, to technologies companies that might not last until 2020 let alone preserve our data in perpetuity or ensure that it’s available and accessible to scholars of the future. We are depending – mostly unthinkingly, I fear – on these platforms to preserve and to not erase, but they are not obligated to do so. The Terms of Service decree that if your “memory” is found to be objectionable or salable, for example, they can deal with it as they deem fit.
Digital data is fragile. The companies selling us the hardware and software to store this data are fragile.
And yet we are putting a great deal of faith into computers as “memory machines.” Now, we’re told, (purportedly) the machine can and should remember for you.
As educational practices have long involved memorization (along with its kin, recitation), these changes to memory – that is, off-loading this functionality to specifically to computers, not to other information technologies like writing – could, some argue, change how and what we learn, how and what we must recall in the process.
And so the assertion goes, machine-based memory will prove superior: it is indexable, searchable, for example. It can included things read and unread, things learned and things forgotten. Our memories and our knowledge and the things we do not know but should can be served to us “algorithmically,” we’re told, so that rather than the biological or contextual triggers for memory, we get a “push” notification. “Remember me.” “Do you remember this?” Memory and indeed all of education, some say, is poised to become highly “personalized.”
It’s worth asking, no doubt, what happens to “collective memory” in a world of this sort of “personalization.” It’s worth asking who writes the algorithms; how do these value knowledge or memory – whose knowledge or memory, whose history, whose stories? Whose gets preserved?

A vision of personalized, machine-based memory is not new. Here is an excerpt by Vannevar Bush, Director of the Office of Scientific Research and Development, whose article “As We May Think” was published in 1945 in The Atlantic:
Consider a future device for individual use, which is a sort of mechanized private file and library. It needs a name, and, to coin one at random, “memex” will do. A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.
It consists of a desk, and while it can presumably be operated from a distance, it is primarily the piece of furniture at which he works. On the top are slanting translucent screens, on which material can be projected for convenient reading. There is a keyboard, and sets of buttons and levers. Otherwise it looks like an ordinary desk.
In one end is the stored material. The matter of bulk is well taken care of by improved microfilm. Only a small part of the interior of the memex is devoted to storage, the rest to mechanism.
…Most of the memex contents are purchased on microfilm ready for insertion. Books of all sorts, pictures, current periodicals, newspapers, are thus obtained and dropped into place. Business correspondence takes the same path. And there is provision for direct entry. On the top of the memex is a transparent platen. On this are placed longhand notes, photographs, memoranda, all sorts of things. When one is in place, the depression of a lever causes it to be photographed onto the next blank space in a section of the memex film, dry photography being employed.
…A special button transfers him immediately to the first page of the index. Any given book of his library can thus be called up and consulted with far greater facility than if it were taken from a shelf. As he has several projection positions, he can leave one item in position while he calls up another. He can add marginal notes and comments….
There’s a lot that people have found appealing about this vision. A personal “memory machine” that you can add to organize as you deem fit. What you’ve read. What you hope to read. Notes and photographs you’ve taken. Letters you’ve received. It’s all indexed and readily retrievable by the “memory machine,” even when human memory might fail you.
Bush’s essay about the Memex influenced both two of the most interesting innovators in technology: Douglas Englebart, inventor of the computer mouse among other things, and Ted Nelson, inventor of hypertext. (And I think we’d agree that, a bit like Nelson’s vision for the associative linking in hypertext, we’d likely want something akin to the Memex to be networked today – that is, not simply our own memory machine but one connected to others’ machines as well.)
But hypertext’s most famous implementation – the World Wide Web – doesn’t quite work like the Memex. It doesn’t even work like a library. As I said a moment ago, links break; websites go away. Copyright law, in its current form, stands in the way of our readily accessing and sharing materials.

While it sparked the imagination of Englebart and Nelson, the idea of a “memory machine” like the Memex seems to have had little effect on the direction that education technology has taken. The development of “teaching machines” during and after WWII, for example, was far less concerned with an “augmented intellect” than with enhanced instruction. As Paul Saettler writes about computer-assisted instruction in his history of ed-tech The Evolution of American Educational Technology, the bulk of these
…directly descended from Skinnerian teaching machines and reflected a behaviorist orientation. The typical CAI presentation modes known as drill-and-practice and tutorial were characterized by a strong degree of author control rather than learner control. The student was asked to make simple responses, fill in the blanks, choose among a restricted set of alternatives, or supply a missing word or phrase. If the response was wrong, the machine would assume control, flash the word “wrong,” and generate another problem. If the response was correct, additional material would be presented. The function of the computer was to present increasingly difficult material and provide reinforcement for correct responses. The program was very much in control and the student had little flexibility.
Rather than building devices that could enhance human memory and human knowledge for each individual, education technology has focused instead on devices that standardize the delivery of curriculum, that run students through various exercises and assessments, and that provide behavioral reinforcement.
Memory as framed by most education (technology) theories and practices involves memorization – like Edward Thorndike’s “law of recency,” for example, or H. F. Spitzer’s “spaced repetition.” That is, ed-tech products often dictate what to learn and when and how to learn it. (Ironically, this is still marketed as “personalization.”) The vast majority of these technologies and their proponents have not demanded we think about either the challenges or the obstacles that digital information technologies present for memory and learning other than the promises that somehow, when done via computer, that memorization (and therefore learning) becomes more efficient.

Arguably, the Memex could be seen as an antecedent to some of the recent pushback against the corporate control of the Web, of education technology, of our personal data, our collective knowledge, our memories. Efforts like “Domain of One’s Own” and IndieWebCamp, for example, urge us to rethink to whom we are outsourcing this crucial function. These efforts ask, how can we access knowledge, how can we build knowledge on our terms, not on the Terms of Service of companies like Google or Blackboard?
The former, “Domain of One’s Own” is probably one of the most important commitments to memory – to culture, to knowledge – that any school or scholar or student can make. This initiative began at the University of Mary Washington, whereby the school gave everyone, students and faculty alike, their own domain – not just a bit of server space on the university’s domain, but their very own website (their own dot com or dot org or what have you) where they could post and store and share their own work – their knowledge, their memory.
On the Web, our knowledge and memory can be networked and shared, and we could – if we chose – built a collective Memex. But it would require us to rethink much of the infrastructure and the ideology that currently governs how technology is built and purchased and talked about. It requires us to counter the story that “technology is changing faster than ever before and it’s so overwhelming so let’s just let Google be responsible for the world’s information.”

Here’s what I want us to ask ourselves, our institutions: who controls our “memory machines” today? Is the software and the hardware (or in Vannevar Bush’s terms, the material and the desk) owned and managed and understand by each individual or is it simply licensed and managed by another engineer, company, or organization? Are these “memory machines” extensible and are they durable? How do we connect and share our memory machines so that they are networked, so that we don’t build a future that’s simply about a radical individualization via technology, walled off into our own private collections. How do we build a future that values the collective and believes that it is the responsibility of the public, not private corporations, to be stewards of knowledge?
We build that future not by being responsible or responsive to technology for the sake of technology or by rejecting technology for the sake of hoping nothing changes. The tension between change and tradition is something we have always had to grapple with in culture. It’s a tension that is innate, quite likely, to educational institutions. We can’t be swept up in stories about technological change and think that by buying the latest gadget, we are necessarily bringing about progressive change.
Our understanding of the past has to help us build a better future. That's the purpose of collective memory, when combined with a commitment to collective justice.
Who controls our memory machines will control our future. (They always have.)
Credits: Slides 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18. Inspired by Dave Cormier’s “Learning in a Time of Abundance” and Abby Smith Rumsey’s When We Are No More; infuriated by ridiculous claims about the future of education technology made by too many people to cite